728x90
반응형
모델 기반 협업 필터링 (Model-based Collaborative Filtering)
- Parametric Machine Learning을 사용하여, 데이터에 내재한 패턴을 이용해 추천하는 CF 기법
- 데이터 정보가 파라미터의 형태로 모델에 압축됨
- 파라미터 → 데이터의 패턴을 표현 → 최적화로 업데이트
Model-based CF의 장점
- 모델 학습 및 서빙: 학습된 모델이 압축된 상태로 저장 → 이미 학습된 모델로 추천하기 때문에 서빙 속도가 빠름
- Sparsity & Scalability 문제 개선: sparse 한 데이터에서도 좋은 성능을 보임 + 데이터가 늘어나도 좋은 추천 성능을 보임
- Overfitting 방지: 전체 데이터의 패턴을 학습하도록 작동 → 특정 주변 이웃에게 크게 영향받지 않음
- Limited Coverage 극복: 특정 유저나 아이템의 유사도를 계산하지 않고도, 전체 데이터 패턴을 기반으로 동작하기 때문에 이웃 유사도 값을 정확하게 계산하지 않아도 잘 추천할 수 있음
- Explicit Feedback Data: 유저의 선호도를 직접적으로 알 수 있는 명시적 데이터 (예: 평점, 좋아요 등)
- Implicit Feedback Data: 유저의 선호도를 간접적으로 알 수 있는 암시적 데이터 (예: 클릭 여부, 시청 여부, 구매 여부 등)
이제 대표적인 Model-based CF 모델 및 기법을 알아보자! 🙌🙌
01. KNN (K-Nearest Neighbors CF)
- NBCF는 유저가 늘어날수록, 연산량도 늘어나서 성능이 떨어지기도 함
- 따라서 특정 아이템 i를 평가한 유저 가운데 타겟 유저 u와 가장 유사한 유저 K명을 사용하여 타겟 유저 u가 내릴 평점을 예측 (보통 K는 25~50값 사용)

01-1. 그렇다면 가장 유사한 개체는 어떻게 찾을까?
두 개체 간 유사성을 수치화하기 위해서는 일반적으로 거리의 역수 개념을 사용
- Mean Squared Difference Similarity
- 각 기준에 대한 점수의 차이를 계산 → 유사도는 유클리드 거리에 반비례
- 분모가 0이 되는 것을 방지하기 위해 분모에 1이 더해짐

- Cosine Similarity
- 추천 시스템에서 가장 많이 사용되는 코사인 유사도
- 두 벡터의 차원이 같을 때, 두 벡터의 각도를 이용하여 구할 수 있음
- 두 벡터가 가리키는 방향이 같을 수록 1, 정반대일수록 -1에 가까움

- Pearson Similarity (Pearson Coreleation)
- 피어슨 유사도(피어슨 상관계수): 각 벡터를 표본평균으로 정규화한 뒤, 코사인 유사도 구함 → 정규화한 덕분에 각 벡터 rating의 크기 차이를 고려할 수 있음
- X와 Y가 함께 변하는 정도 ÷ X와 Y가 따로 변하는 정도
- 1에 근접 — 양의 상관 관계
- 0 — 서로 독립
- -1에 근접 — 음의 상관 관계
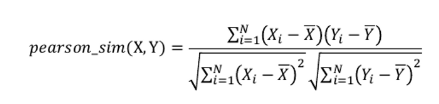
- Jaccard Similarity
- 벡터를 집합의 개념으로 변환하여 유사도를 측정 → 길이(차원)이 달라도 이론적으로 유사도를 계산할 수 있음
- 두 집합이 같은 아이템을 얼마나 공유하고 있는지 보여줌
- 두 집합이 가진 아이템이 모두 같을수록 1, 겹치지 않을수록 0
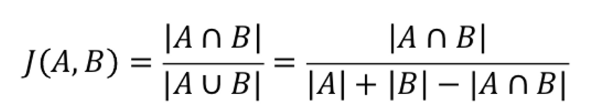
01-2. 인접 벡터를 더 빨리 찾을 수는 없을까? (ANN)
- Brute Force KNN보다 정확도는 떨어져도, 근사해법을 통해 인접 벡터를 더 빨리 찾고자 한다! (ANN, Approximate Nearest Neighbor)
- ANNOY
- 주어진 벡터 중 임의의 두 벡터를 선택하여 Vector Space 나누기
- Subspace에 있는 벡터의 개수를 node로 하여, 각 space 내에 K개가 초과하지 않도록 space를 반복해서 나누기
- 다른 ANN에 비해 간단하고 가벼우며, 탐색할 이웃의 개수를 알고리즘이 보장
- acc ↔ speed Trand off 가능
- 단, 이미 생성된 tree에 새로운 데이터를 추가할 수 없음
- Hierarchical Navigable Small World Graphs (HNSW)
- 벡터를 노드로 표현 및 인접한 벡터를 edge로 연결 후, Layer에 따라 표현되는 노드를 계층적으로 random sampling
- 최상위 계층(최소 노드)에서 임의의 노드에서 시작 노드로 가는 길 찾기
- 만약 탐색 layer에 길이 없다면, 하위 layer로 이동하여 길찾기 반복
- Inverted File Index (IVF)
- 주어진 vector을 n개의 클러스터로 나누어서 저장
- query vector가 속해있는 클러스터 찾기
- 해당 클러스터 내에 있는 vector에 대해서만 탐색
- 탐색하고자 하는 클러스터 개수를 증가실수록 정확도 ↔ 속도 trade-off
- Product Quantization - Compression (PQ)
- 기존 vector을 n개의 sub-vector로 나눔
- 각 sub-vector군에 대해 k-means clustering을 통해 centroid 구하기
- 기존의 모든 vector를 n개의 centorid로 압축해서 표현
- Centorid 사이의 유사도를 계산 → O(1)의 연산
- PQ와 IVF를 동시에 사용해서 더 빠르고 효율적인 ANN 수행 가능 — faiss 라이브러리에서 제공
02. Singular Value Decomposition (SVD)
Rating Matrix R 에 대해서 유저와 아이템의 잠재 요인(latent factor)을 포함할 수 있는 행렬로 분해하는 것 — PCA와 같이 차원 축소 기법으로 분류됨
Latent Factor Model (잠재 요인 모델): 유저와 아이템의 관계를 잠재적으로 표현할 수 있다고 보는 모델
→ Rating Matrix를 저차원의 행렬로 분해 하는 방식으로 작동
→ 각 차원의 의미는 모델 학습을 통해 생성 및 표면적으로 알 수 없음
→ 같은 벡터 공간에서는 유저와 아이템의 유사한 정도를 알 수 있음

- 유저 잠재요인 행렬(U) = (M×M) M명의 유저에 대해서 K차원 행렬로 표현
- 잠재요인 대각행렬 (S) = (M×K) 유저 행렬과 아이템 행렬을 잇는 역할로, Latent Factor의 중요도를 나타냄 (대각행렬이기 때문에 대각선 외 모두 0) → K값이 M, N인 경우: full SVD → K값이 M, N이하의 값인 경우: Truncated SVD — 일부 특이치만으로도 부분 복원 및 요약이 가능하다는 개념
- 아이템 잠재요인 행렬(V^T) = (K×N) N개의 아이템에 대해서 K차원 행렬로 표현
02-1. SVD의 한계
- 분해하려는 행렬이 Sparse하다면, 분해 작업을 수행하기 어려움
- 따라서 결측치를 임의의 값들로 채워(Imputation) SVD 수행 → 정확하지 않은 Imputation은 데이터 왜곡 및 예측 성능 저하
- SVD의 원리를 차용하되, 다른 접근 방법이 필요 → Matrix Fatorization
03. Matrix Factorization (MF)
- Rating Matrix를 저차원의 User와 Item Latent facor 행렬의 곱으로 분해
- 단, 관측된 선호도(평점)만 사용하여 모델링한다!
- Rating Matrix를 P와 Q로 분해하여, R과 최대한 유사하게 R_hat을 최적화
- $R \approx P \times Q^T = \hat{R}$
- 목적식의 전항은 유저(아이템)의 u(i) latent vector 목적식의 후항은 과적합 방지를 위한 L2 정규화(Regularization) 목적식의 최적화 함수로는 SGD 사용 → ALS로 개선 가능

03-1. ALS (Alternative Least Square) for Param Update
- 유저와 아이템 매트릭스 중 하나를 상수로 놓고 나머지 매트릭스를 번갈아가면서 업데이트하는 것
- 위 방법을 사용하면 목적함수가 2차함수가 되어 convex → global min을 찾을 수 있음
- SGD보다 Robust하며, 대용량 데이터 병렬처리가 가능함

03-2. 암시적 데이터(Implicit)를 고려한 목적함수
- ALS 매트릭스 연산을 통해서 암시적 데이터에 대해서 효율적으로 연산한다!
- 암시적 데이터의 내적값이 0 또는 1로 나오는데, 실제값과 내적값의 차이를 얼마나 반영할지를 confidence와의 곱으로 조절하도록 함
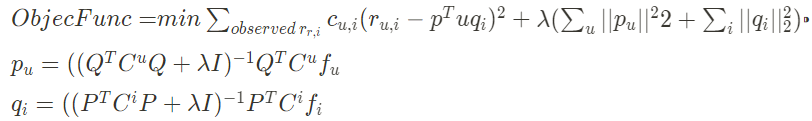
03-3. 다양한 테크닉을 추가한 MF with bias, conf, temp
- Adding Biases: 유저/아이템의 편향을 반영 → 전체 평균, 유저와 아이템의 bias를 추가하여 예측 성능을 높임

- Adding Confidnece Level: 평점에 따른 신뢰도를 반영 (c_{u,i})
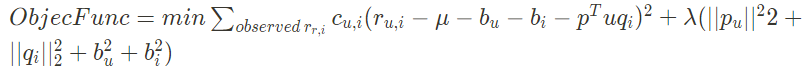
- Adding Temporal Dynamics: 시간에 따른 변화를 반영 (t)
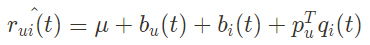
728x90
반응형



