728x90
반응형
문제
N개의 수가 주어졌을 때, 이를 오름차순으로 정렬하는 프로그램을 작성하시오.
입력
첫째 줄에 수의 개수 N(1 ≤ N ≤ 1,000,000)이 주어진다. 둘째 줄부터 N개의 줄에는 수가 주어진다. 이 수는 절댓값이 1,000,000보다 작거나 같은 정수이다. 수는 중복되지 않는다.
출력
첫째 줄부터 N개의 줄에 오름차순으로 정렬한 결과를 한 줄에 하나씩 출력한다.
예제 입력 1
5
5
4
3
2
1
예제 출력 1
1
2
3
4
5
첫 번째 풀이 (내장 sort 이용)
import sys
input = sys.stdin.readline
nums = [int(input()) for _ in range(int(input()))]
for i in sorted(nums):
print(i)
- 수를 입력받고, 내장 sort 함수를 사용해 정렬하여 출력하여 간단하게 풀이하였다
- 이 때, readline을 이용하지 않으면 시간 초과가 남에 유의
- 값을 입력받는 것을 제외한 내장 정렬 함수의 시간 복잡도는 O(NlogN)
두 번째 풀이 (counting sort 이용)
import sys
from collections import defaultdict
input = sys.stdin.readline
nums = defaultdict(int)
for _ in range(int(input())):
nums[int(input())] += 1
for i in sorted(nums.keys()):
print(i * nums[i], end='\n')- 수를 입력받고, 그 수가 몇 개나 들어있는지 DefaultDict를 활용하여 저장한다
- 입력받은 수의 종류를 정렬하고, 각 수의 개수만큼 출력한다
- 정렬하는데 드는 시간복잡도는 O(KlogK) (K는 입력받은 수의 종류 수를 의미)
풀이 시간 비교
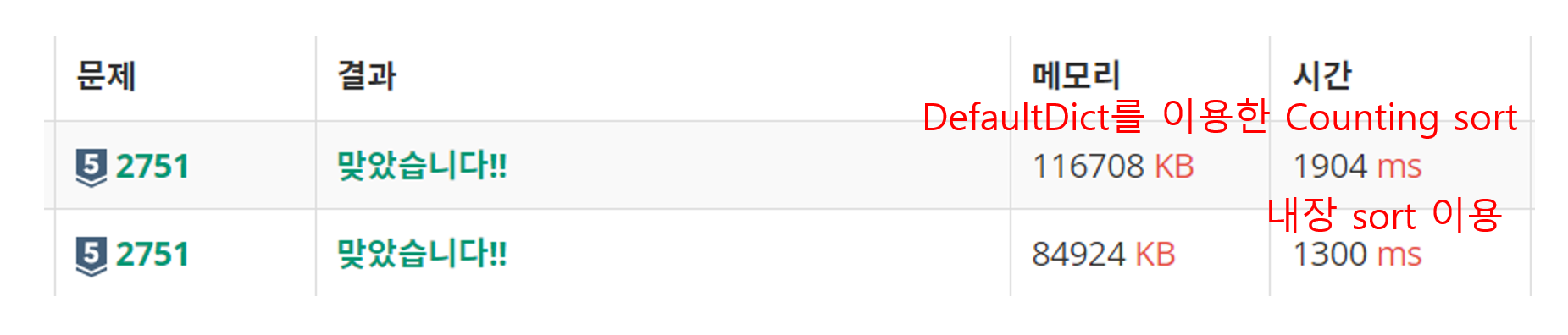
- 아래 풀이: 내장 sort를 이용한, 첫 번째 풀이 방법
- 위의 풀이: defaultdict를 이용한 counting sort로, 두 번째 풀이 방법
- 이론상으로는 counting sort를 이용한다면, 미세하게라도 더 빨라야한다! 하지만 본 풀이에서는 오히려 시간이 더 많이 소요되었다.
- 그 이유에 대해서 추론해보자면, 원래 일반적인 counting sort를 이용할 때는 리스트를 이용하게 된다. 하지만 내가 작성한 코드에서는 편의상 DefaultDict를 사용했고, 이게 영향을 미치게 되지 않았나 생각한다.
- 또한 첫 번째 풀이에서는 list comprehension을 통해서 데이터를 저장했으나, 두 번째 코드에서는 for문을 통해서 데이터를 입력받아 저장했기 때문에, 본 파트에서 시간이 더 소요된 것 같다.
728x90
반응형
'Dev > BAEKJOON 백준' 카테고리의 다른 글
| [백준/BOJ] 백준 코딩 알고리즘 14889번 스타트와 링크 Python (0) | 2023.08.16 |
|---|---|
| [백준/BOJ] 백준 코딩 알고리즘 11053번 가장 긴 증가하는 부분 수열 Python (1) | 2023.08.16 |
| [백준/BOJ] 백준 코딩 알고리즘 10988번 팰린드롬인지 확인하기 Python (0) | 2023.08.14 |
| [백준/BOJ] 백준 코딩 알고리즘 1149번 RGB거리 Python (0) | 2023.08.06 |
| [백준/BOJ] 백준 코딩 알고리즘 1929번 소수 구하기 Python (0) | 2023.08.05 |